Batch Processing
Overview
Batch processing is the processing of a large volume of data all at once in a scalable and distributed fashion. The data easily consists of millions of records for a day and can be stored in a variety of ways (file, record, etc). Jobs that can run without end-user interaction, or can be scheduled to run as resources permit, are called batch jobs. An example of a batch job is processing all of the transactions a financial firm might submit for a week to gain statistical insights.
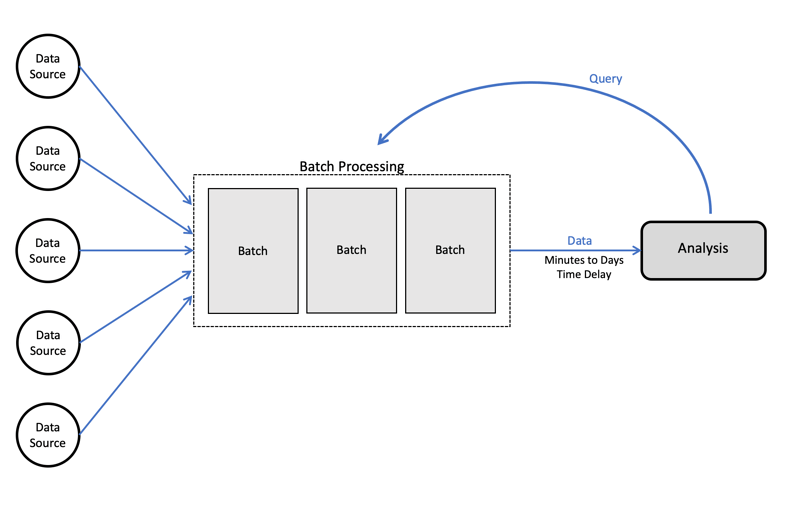 source: upsolver.com
source: upsolver.com
Purpose
It helps to reduce the operational costs that businesses spend on labor as it does not require specialized data engineers to support it’s functioning. Using batch processing can reduce a company’s reliance on other expensive pieces of hardware, making it a relatively inexpensive solution that helps businesses save money and time. Batch jobs are running offline in the background making less impact on the system resources. It can take a large amount of time for these jobs to finish processing. Running the jobs offline, gives the managers ultimate control over when to start processes, whether it be overnight or at the end of the week or some trigger mechanism. Once installed and established, a batch system doesn’t involve heavy-duty maintenance, making it a relatively low-barrier-to-entry solution.
Use cases
It is used in situations where you don’t need real-time analytics results, and when it is more important to process large volumes of data to get more detailed insights than it is to get fast analytics results. Complex algorithms that need to access the entire datasets are implemented as the batch jobs. ETL (Extract, Transform, Load) can be also implemented as batch jobs.
- End-of-day trade processing
- Fraud surveillance
- Orders from customers
- Customer segmentation
- Customer targeting
- Analyzing customer search history
- Personalizing search results
- Insights about trending
- Custom emails
Tools
Open-source
- Apache Spark
- Hadoop MapReduce
- Apache Hive
- Apache Beam
- Python Dask
Cloud providers
- Amazon EMR
- Azure HDInsight
- Google Cloud Dataproc
- Databricks
